4월이다. 시간 참 빠르다. 빠른만큼 느리다. 것도 그런것이, 올해들어서 술을 끊고 있어서 벌써 85일 정도 되었고 그 만큼 남는 저녁시간에 할꺼 다 해도 시간이 남는다. 수면은 규칙적으로 돌아왔고, 여느해보다 공부량을 엄청나게 늘렸지만서도 시간이 남는 것은 사실인 것 같다.
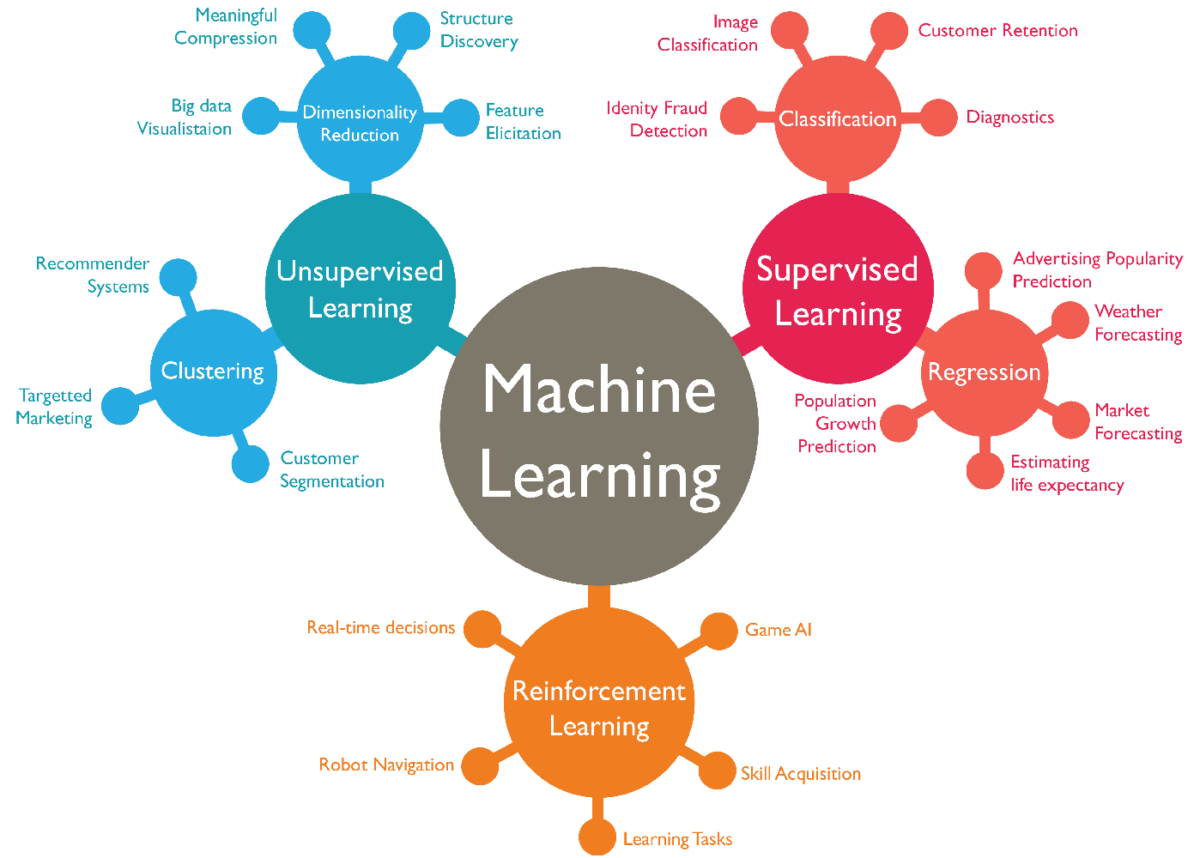
지난번에 TA에서 호되게 당한 이후로 스스로 마음이 엄청나게 긴장했는지, 3월을 내내 머신러닝 속에 살았다. 지난 3주간 학교강의와 인터넷 강의를 들으면서 기본적으로 선형회귀, 로지스틱회귀 그리고 딥러닝에 대해서 배웠고, 회귀분석은 어느정도 코딩까지 해봤다. 100%까지는 아니지만, 적어도 한달전에 비해서는 크게 이해가 되는 것은 사실이다.
최근에 딥러닝을 배우고 “아 이거다!” 라는 생각이 들었다. 미분과 선대가 기본이 되는 이 과정속에, 사실 클라우드 시스템을 적용하면 딥러닝 시스템을 구축하는 것은 크게 일도 아니라는 느낌을 받았다. 아 그래서 풀스택 딥러닝이라는게 있는거구나. 그리고 좀더 명확히 말하면, 내가 좀더 집중해야 할 부분이 딥러닝이라는 사실을 알았다. 결국 컴퓨팅 파워가 가장 많이 들어가는 부분이기도 하고, 어쩌면 지금 내가 분산처리와 클라우드 등에 대해, 그 아키텍처를 구현하는데에 당연스럽게 필요한 부분이기도 했다.
한 달간의 머신러닝의 공부 과정은 결국 빅픽처를 이해하는 과정이었다. 머신러닝의 수 많은 기법들, 이에 대한 장단점을 알고, 어느 상황에서 쓰이는지를 알면 결국 머신러닝도 하나의 툴로써 작용을 하는 것이다. 데이터와, 문제의 상황에 맞게. 그리고 이는 어쩌면 좀더 명확하게 비즈니스와 연관이 되는 것을 알았다. 새로운 AI프로덕트로 비즈니스를 창출한다.. 이런거 말고, 어떤부분에서 비용을 줄이고, 어떤 신선한 아이디어로 고객을 유치하는것인지 말이다.
뭐 그런 머신러닝 관련 얘기는 아마 꾸준히 할 것 같다. 어차피 취미인데 뭐. 오늘 글을 쓰고싶은 것도 이와 관련된 것이다. 난 솔직히 말해서 머신러닝이 아직까지도 뜬구름 잡기 같은 느낌이다. 연구분야와 관련 기술이 엄청나게 쏟아지는 것은 사실이다. 개발자로써, 새롭게 쏟아지는 기술속에 발을 담그고 있으면 행복한 것은 당연하지만, 5~10년정도 된 이 분야로 내가 완벽하게 pivot하기에는 꽤나 큰 리스크가 있다는 생각이다. 데이터 엔지니어가 적어도 지금 내 동네에서는 수요가 많이 줄었듯이 (물론 데이터를 다루는 SWE수요는 그대로지만) MLE처럼 domain-specific한 직업이 얼마나 갈 수 있을까, 물론 해보지 않고는 모르는 것이 정답이지만 더 이상 리스크를 감당하지 말자고 스스로에게 다짐을 하고 나서 바라본 머신러닝의 세계는, 인터넷이 처음 도래했을 때의 ‘정보의 홍수’ 처럼, 말 그대로 정보의 홍수이다.
공부할 것이 너무 많다. 정확히 말해서, 매력적으로 보이는것이 정말 많다. 데이터과학을 공부하고 싶을때에도 그랬다. 데이터 사이언스 관련되서 얼마나 많은 정보가 인터넷에 흘러왔던가. 그래서 데이터를 공부하고자 했는데 기본적인 수학이나 파이선이나 주피터 노트북 조차 헷갈려서, 그렇게 흐름을 놓쳤다. 그게 불과 3년전 정도인 것 같다. 그리고 지금의 흐름은 데이터 과학보다 좀더 ‘많은’ 기술적인 것들을 포함한 ML이 도래했다. 난 ML이 하나의 커다란 라이브러리 같다. 데이터 과학에 쓰이는 넘파이처럼, scikit-learn, pytorch, tensorflow모두가 라이브러리 아니던가. 오픈소스던, 기업에서 만든 라이브러리던. 이건 결국 이를 정말 매력적으로 만들어서 관련 기술을 ‘돈주고’ 써주세요 라고 하는 기업들의 고도의 마케팅 전략과도 비슷하다. 물론, 수 많은 기능들이 공짜로 오픈되어 있는데, 안쓸 이유는 없지만 결국 어떤 문제해결을 위한 computing power가 돈이 되는 세상속에, FAANG을 비롯한 회사들이 매혹적으로 보이는 라이브러리를 푸는 이유가 어쩌면 당연하다고 해야할까.
라이브러리 뿐만 아니라 학교에서도 적극 이를 가르치고, 유튜브에 널려있는 강의들, 모든게 다 연관이 있다고 봐야한다. 물론 난 이에 대해서 나쁜 의미를 가지고 있지는 않다. 다만, 너무 ‘공짜로’ 들을 수 있는게 많다보니깐 전과 똑같은 상황이 발생한다. Udemy나 코세라에 사둔 ‘싼’ 강의들이 얼마나 많던가. 사두고 하지도 않았던 것들이 말이다. 그런데도 지금은 또 보면 공부할 것들이 산더미처럼 쏟아지고, 그런 공부할 것들이 많은것은 좋은데 과연 이 와중에 내 ‘본업’을 신경쓸 수는 있을까 라는 원천적인 고민이 생긴다는 것이다.
최근에는 면접을 진행하고 있다. 아직 본격적이지는 않지만, 체감상으로 확실한 것은 일단 프론트앤드 수요는 많이 줄은 것 같다. 아니면 정말 프론트엔드에 ‘특화된’ 사람이거나. 이곳 실리콘벨리의 특징이 그렇다. 어느정도 ‘누구나’ 쓸 수 있는 기술이 되면 중국, 인도등으로 기술이 전파되고, 그곳에 사람들이 ‘값싼’ 인력이 된다. 그럼 더 이상 예전의 기술만으로 먹고살기 힘들게 된다. 프론트앤드가 가장 빨리 털릴(?) 것 같다는 내 추측이 대략 맞는 것 같다. 그럼 백엔드? 풀스택? 백엔드도 스프링만 봐도 조금만 틀 잡아두면 찍어내기(?)는 그리 어렵지 않다. 그럼 어떤 레벨로 올라가야 하는가? 결국에 보면 아키텍처링이 가능한, 도메인에 특화된, 풀스택만 살아남을 수 있다고 봐야할 것 같다.
말이 어렵지만 뭐 단순히 MERN스텍으로 나 백엔드,프론트앤드 다 할줄알아 라는게 아니라 기본적인 REST와 이에 해당되는 privacy, data handling (pagination같은), security (OAuth, CSRF, CORS) 부터 해서 프론트쪽에서도 Caching, CDN, Cookie Mgmt, MVVC구조랑 데이터 핸들링까지. 이렇게 구현한 것을 dockerizing해서 이를 multiple container로 관리되는 kubernetes환경에, load balancing정책부터, 요청등을 MQ로 관리하고, 전체적인 아키텍처와 더불어 CI/CD가 원클릭으로 가능한 환경. 이런 기본적인 인프라와 시스템 디자인에 더불어 아주아주 기본적으로 탄탄한 ‘코딩’ 과 디자인 패턴이 기반이 되어야 한다는 것이다. 사실 나같은 경우엔 유라임과 전 회사에서 죄다 다뤄왔던 것이지만, 어쩌면 스타트업에서 founding member로써 CTO가 초기 기반 다지는 행동에 해당되는 이 모든것들이 이젠 자금을 계속 줄여나가야 하는 회사 입장에서는 슈퍼개발자 한명을 절실히 필요로 한다는 것이다.
내가 가장 빈약한(?) 부분이 코딩과 알고리즘인 것 같다. 자료구조는 어느정도 익숙해졌지만, 알고리즘을 코딩문제에 응용하는 것은 아직도 약하다. 작년 말부터, 아니 어떻게보면 한 4~5년은 리트코딩을 하곤 했는데 이게 결국 기본기를 익히는 훈련인 것이다. 그런데 최근에 머신러닝 한답시고 기본기를 다지는 훈련을 안했으니, 인터뷰를 보면 당사자는 “쟤는 기본도 안되면서 무슨 말로만 시스템디자인 이런얘기를 하는것인가?” 라는 느낌이 들꺼다. 이번달 초에 A사 면접에서 살짝 느낀것도 있었다. 좀 부끄러웠다. 그런데도 정신을 못차리고 (사실 TA에게 휘달려서 멘붕이었던 것도 있지만) 밤낮으로 머신러닝만 붙잡고 있었으니 내가 머신러닝의 ‘자료의 홍수’에 대해서 글을 쓸 만도 하다.
어쨌든 내 커리어의 빅픽처는, SWE하면서 MLE경험 2~3년정도 하고, Engineering Manager 이후에 AI-PM으로 나아가서 C-level로 올라가는게 목표다. 7~10년정도 예상하고 있는 이 커리어에서, 내가 꼭 상기해야 할 것은 ‘좋아하는 것보다, 잘하는 것을 하자’ 라는 것. 어차피 개발이 다 좋긴 하지만, 지금은 기본기를 다져야 할 때인 것 같다. 그렇게 섭렵할 수 있는 시간이었으면 좋겠다. 수없이 많은 머신러닝 강의들을 하나 둘 쳐내서, 마치 머릿속에 Queue가 하나 있는 것처럼. 나라는 사람이 어차피 한정되어 있으니, 거기서 나 스스로를 가지치기 할 수 있는 스스로가 되는 마음에서, 최근에 ‘관심있게’ 본 강의 몇 개를 스스로 지워나간다.

