Multiple features (variables)
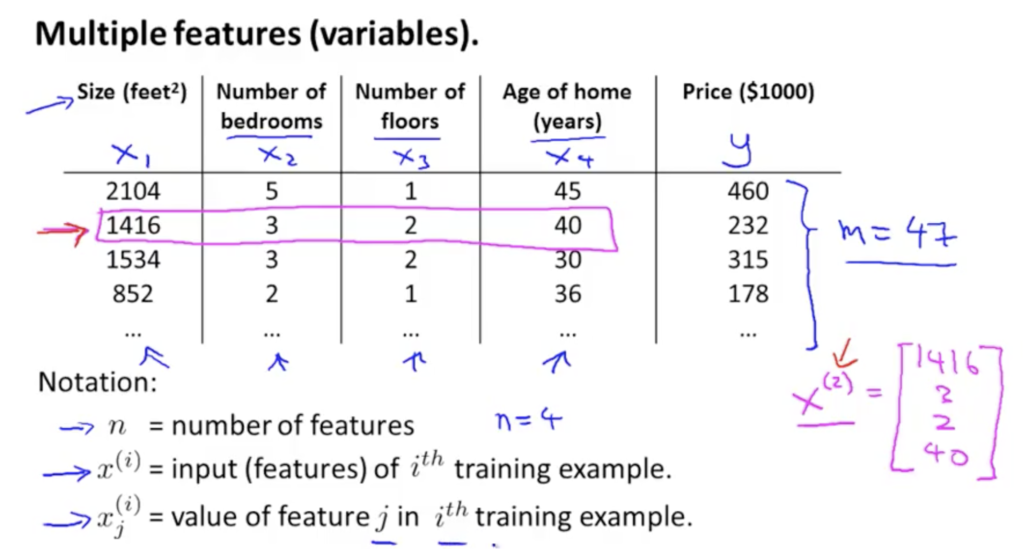
위 데이터에서 n = 4, m = 47가 된다.
![x^{(2)} = \left[\begin{matrix}1416\\3\\2\\40\\\end{matrix}\right]](https://s0.wp.com/latex.php?latex=x%5E%7B%282%29%7D+%3D+%5Cleft%5B%5Cbegin%7Bmatrix%7D1416%5C%5C3%5C%5C2%5C%5C40%5C%5C%5Cend%7Bmatrix%7D%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
(2)는 x의 승수가 아니라, 2번째 값을 의미.
Hypothesis: 

ex)

Hypothesis 함수에 대한 multivariable form은 아래를 만족한다.
For convenience of notation, define 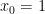
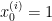

위 데이터와 비교하면, 여기서 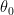
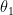
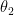


![x = \left[\begin{matrix}x_0\\x_1\\x_2\\...\\x_n\\\end{matrix}\right]](https://s0.wp.com/latex.php?latex=x+%3D+%5Cleft%5B%5Cbegin%7Bmatrix%7Dx_0%5C%5Cx_1%5C%5Cx_2%5C%5C...%5C%5Cx_n%5C%5C%5Cend%7Bmatrix%7D%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\theta = \left[\begin{matrix}\theta_0\\\theta_1\\\theta_2\\...\\\theta_n\\\end{matrix}\right] \in \mathbb{R}^{n+1}](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5Cleft%5B%5Cbegin%7Bmatrix%7D%5Ctheta_0%5C%5C%5Ctheta_1%5C%5C%5Ctheta_2%5C%5C...%5C%5C%5Ctheta_n%5C%5C%5Cend%7Bmatrix%7D%5Cright%5D+%5Cin+%5Cmathbb%7BR%7D%5E%7Bn%2B1%7D&bg=ffffff&fg=000&s=0&c=20201002)
여기서 ![\left[\begin{matrix}\theta_0&\theta_1&...&\theta_n\end{matrix}\right] = \theta^{T}](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bmatrix%7D%5Ctheta_0%26%5Ctheta_1%26...%26%5Ctheta_n%5Cend%7Bmatrix%7D%5Cright%5D+%3D+%5Ctheta%5E%7BT%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\left[\begin{matrix}x_0\\x_1\\...\\x_n\end{matrix}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bmatrix%7Dx_0%5C%5Cx_1%5C%5C...%5C%5Cx_n%5Cend%7Bmatrix%7D%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\left[\begin{matrix}\theta_0&\theta_1&...&\theta_n\end{matrix}\right] \left[\begin{matrix}x_0\\x_1\\...\\x_n\end{matrix}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bmatrix%7D%5Ctheta_0%26%5Ctheta_1%26...%26%5Ctheta_n%5Cend%7Bmatrix%7D%5Cright%5D+%5Cleft%5B%5Cbegin%7Bmatrix%7Dx_0%5C%5Cx_1%5C%5C...%5C%5Cx_n%5Cend%7Bmatrix%7D%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)

=> 이를 Multivariate linear regression이라고 한다.
다변수를 위한 경사하강법
Hypothesis:
Parameters:
Cost Function:
Gradient descent:
Repeat {
} (simultaneously update for every j = 0,….,n)
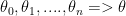
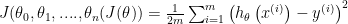

새로운 알고리즘을 적용하면 (기존에

연습1 – Feature Scaling
Idea: Make sure features are on a similar scale.
E.g.

단순 cost function으로는 시간이 오래걸림.
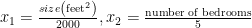


Mean normalization
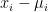
e.g. 

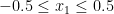

(여기서 
(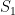
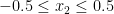

연습2 – Learning Rate
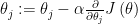
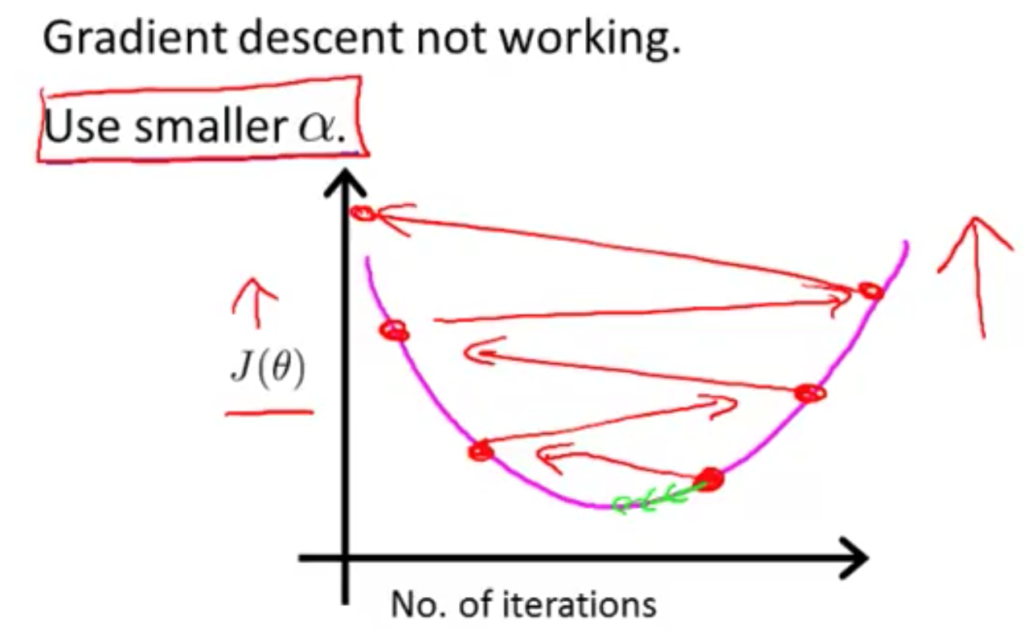
- “Debugging”: 경사하강법이 정상 동작하는지 확인하는 방법
- 어떻게 learning rate인
를 정할 것인가.
정상 작동: 
(경사 하강의 반복 숫자가 수렴하는 반복 횟수는 모든 경우에 따라 다름)
수렴하는지 확인하려면 그래프를 그려 수렴하는지 확인해야 한다. 혹은, 자동으로 수렴하는 것을 아는 방법이 있다.
자동 수렴 확인: 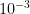

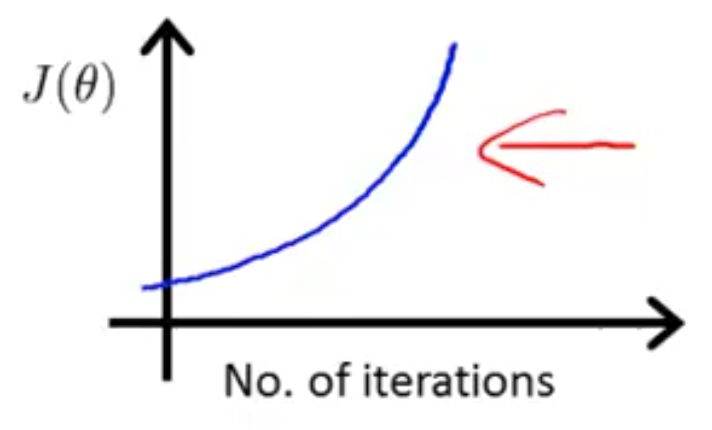
충분한 알파값을 가질 때, cost함수는 모든 반복에서 무조건 감소한다. 하지만 알파가 너무 작으면 너무 느리다. 수차례 반복하고 나서야 최소값에 도달한다.
보통 gradient descent는 0.001, 0.001, 0.1, 1 처럼 빠르게 감소할 때의 알파값을 찾은 후, 여기서 찾는다.
Features and Polynomial Regression
집값 예측 모델:
여기서 frontage가 x1, depth가 x2
area => x = frontage * depth
이는 집의 넓이기 떄문에 아래와 같이 하나만 가지고 정의가 가능하다. (곱이기 떄문에)
즉, x1, x2의 두 개를 가져갈 필요는 없고, 새로운 x를 정의하면 됨.
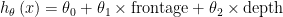
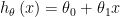
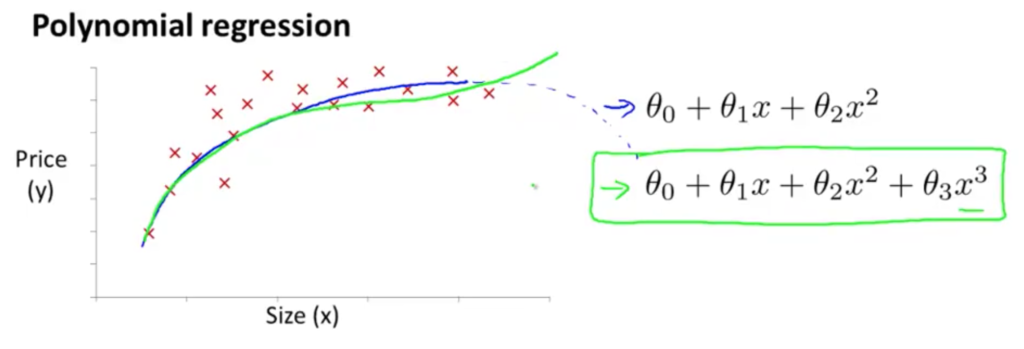
어떻게 데이터를 잘 표현하는 식을 구하나
다변수 선형 회기를 사용!
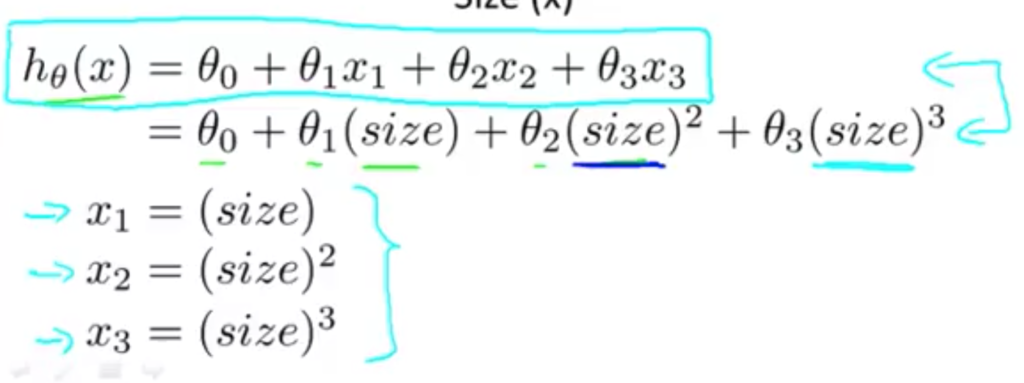
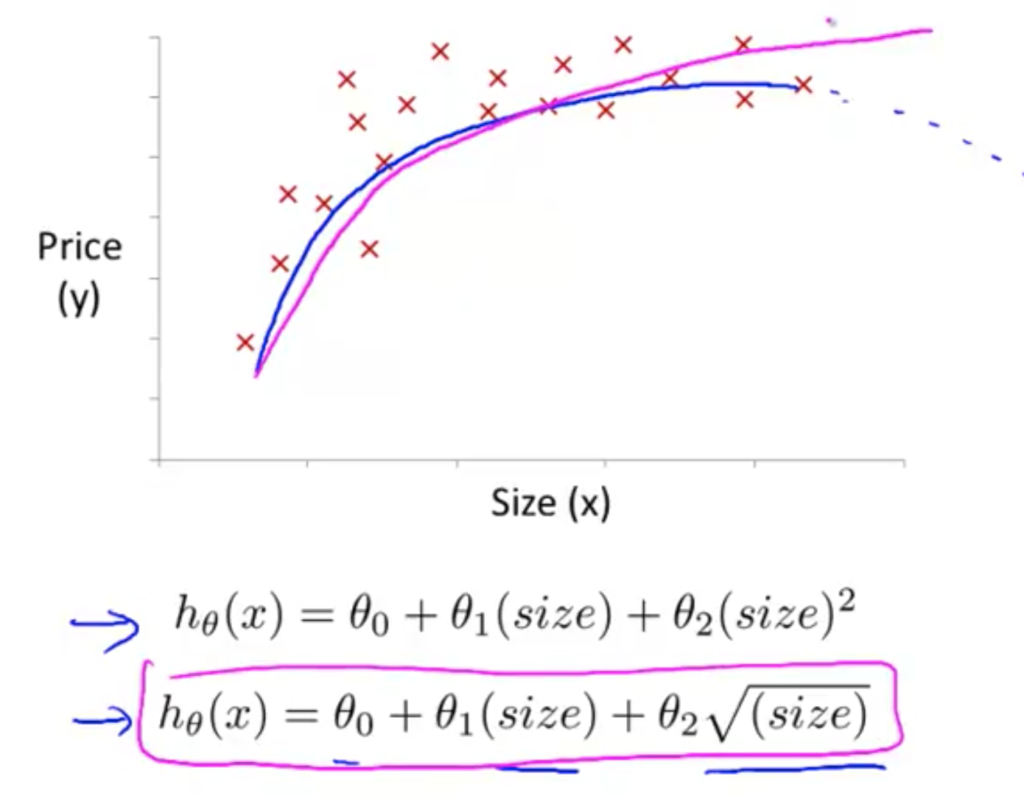
Feature의 선택
Normal Equation
시작: 만약 1D (
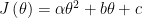
여기서 알파값을 구하는 것은 미분해서 0이되는 구간을 구하면 되긴함.
우리가 궁금해 하는 것은,
(
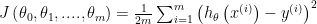
경사하강법
(단점)
– 알파를 정해야 한다.
– 많은 반복이 필요하다.
(장점)
– n이 많을 때에도 잘 동작한다.
정규방정식(Normal Equation)
(장점)
– 알파를 정할 필요가 없다.
– 반복이 필요없다.
(단점)
– 계산이 많이 필요하다.: 

– n이 매우 크면 엄청 느리다. (반대로 n이 작으면 좋음. n이 100~1000정도면 괜찮음.)
=> 문제에 따라 선택하기!
불필요한 feature가 있는지 먼저 확인. 없으면 non-invertible문제가 해결된다.